TL;DR: 本文是一篇AI绘画从理论到实操的专业指南。它揭示了扩散模型机制,并提供了一套包含语义底图、结构锁定、风格统一和高阶放大的四步商业级操作链路,旨在帮助创作者从简单的提示词堆砌转向精准的视觉控制。
AI绘画本质上是利用深度学习模型将文本描述转化为视觉图像的技术,其核心在于通过大规模数据集训练的潜空间映射,重构视觉元素的概率分布。到2026年3月,AI绘画已从最初的视觉惊艳期,进入与专业工作流深度融合的实操阶段。
单纯依赖提示词(Prompt)的创作模式正在贬值。由于自然语言处理能力的提升,模型能自动补全用户意图,导致简单的词汇堆砌失去竞争力。目前的核心竞争力已转移至对视觉语言的掌控力,以及通过控制模型(ControlNet)和自定义训练集(LoRA)精准锁定图像细节的能力。
理解扩散模型(Diffusion Model)机制是避免“随机抽卡”的前提。该模型在训练时将清晰图片逐步加噪至随机像素,生成时则逆转此过程。当你输入指令,AI是在高维数学空间(潜空间)中寻找语义相近的概率分布,从随机噪声中迭代还原图像。这种机制决定了同一提示词在不同种子值(Seed)下会产生截然不同的结果。
要产出可商用的商业插画,需要建立一套可验证的操作链路:
第一步:构建语义底图。舍弃 Beautiful 或 Stunning 等泛化形容词,采用“材质+光影+构图+核心主体”的结构。例如:2026年东京街头,雨后霓虹灯反射,电影级宽幅构图,主体为穿着透明材质雨衣的赛博朋克风格女性。建议降低 Stylize 值以提高文本忠实度。若出现手指或眼睛形变,直接使用局部重绘(Inpainting)而非修改词汇,因为形变属于概率随机问题。
第二步:结构锁定。利用 ControlNet 将 AI 从随机生成转为精准控制。在 Stable Diffusion 中上传参考姿势图或线稿,选择 Canny(边缘检测)或 OpenPose(姿势检测)模型,将权重(Weight)设在 0.6-0.8 之间。若边缘过于生硬,可调高结束步数(Ending Control Step),让 AI 在最后 20% 的迭代中拥有自由度,以实现自然融合。
第三步:风格统一。商业项目需通过 LoRA(低秩自适应)模型确保视觉语言一致。在 Civitai 或私有库中选择特定画风 LoRA,权重建议控制在 0.3-0.6 之间,过高会导致图像过曝或出现伪影。若出现色彩崩坏,可通过调整 VAE 解码器修正,确保全组作品在色调与笔触上高度统一。
第四步:高阶放大。针对打印或高清显示需求,使用潜空间放大(Hires. fix)或 Tiled Diffusion。在 Extras 选项卡中选择 R-ESRGAN 4x+ 或 SwinIR 算法,将重绘幅度(Denoising strength)设定在 0.3-0.5 之间。低于 0.3 缺乏细节增加,高于 0.5 则会改变原图内容。同时开启 Tiled VAE 以防止显存溢出,确保皮肤毛孔、织物纹理等细节自然增强。
工具选择应基于具体需求:
Midjourney v7 适合追求美感且不希望调整参数的用户。审美水准高且速度快,但闭源且无法本地微调,每月订阅费 30-60 美元,适用于概念草图和社交媒体配图。
Stable Diffusion 3.5 适合需要绝对掌控权的专业设计师。完全开源且插件丰富,但上手门槛高,建议配备 24GB 显存以上的显卡,适用于商业产品设计和精准人像定制。
Flux.1 核心优势在于文字渲染的精准度和真实感,尤其适合需要将文字融入图像的广告设计场景。
AI绘画仍存在明显的边界限制。首先是高精度逻辑结构,如复杂的机械钟表传动,AI 易生成看似合理但物理上无法运转的假结构。其次是具有叙事背景的微表情,AI 难以捕捉违背常规概率的微妙眼神,这类“灵气”仍依赖人类观察。
关于 AI 摧毁绘画动力的焦虑,可以参照摄影术的历史。摄影术并未杀死绘画,而是将绘画从写实主义的负担中解放,催生了印象派。AI 正在接管重复性的执行工作,迫使创作者向创意策划、审美判定等更高维度迁移。选择权本身就是一种创作:从万张生成图中选出触动灵魂的一张,是人类在为概率分布提供价值判定。
建议创作者停止在执行效率上与 AI 竞争,转而将其作为外挂大脑。采用“人类导演 + AI 执行”的协作模式:利用 AI 快速迭代 10 个视觉方向,挑选最具潜力的方案,再通过手工绘制或深度重绘完成。现在应优先建立私有 LoRA 库将个人风格数字化,这比钻研提示词更有长期价值。\n \n
\n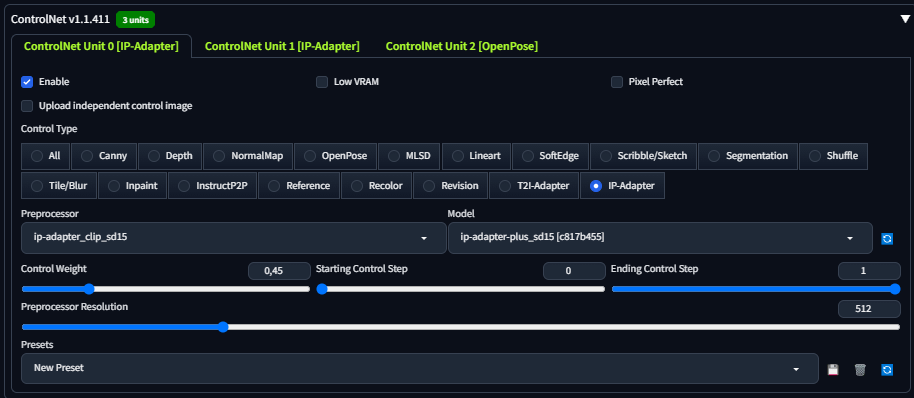 \n
\n \n
\n \n
\n